Forrest Glines
Metropolis Postdoctoral Fellow in Exascale Computational Astrophysics
T-2, Theoretical Division, Los Alamos National Laboratory
Department of Physics and Astronomy, Michigan State University
Department of Computational Mathematics, Science and Engineering, Michigan State University
Biography
I am a Metropolis Postdoctoral Fellow at Los Alamos National Laboratory studying astrophysical plasmas using exascale GPU-based resources. My work at Los Alamos is currently focused on developing AthenaPK, an exascale magnetohydrodynamics code, and Parthenon, the adaptive mesh refinement framework that powers AthenaPK. With AthenaPK, I run simulations of astrophysical jets in various scenarios on Frontier, the world’s first exascale supercomputer.
My computational intrests focus on enabling scientific computing on GPUs via the development of performance-portable codes: codes that are capable of high performance on various GPU and CPU architectures.
Feel free to contact me for collaboration via email.
Download my resume.
-
PhD in Astrophysics and Computational Mathematics, Science and Engineering, 2022
Michigan State University
-
BSc in Physics and Mathematics with Emphasis in Applied and Computational Mathematics, 2016
Brigham Young University
Projects


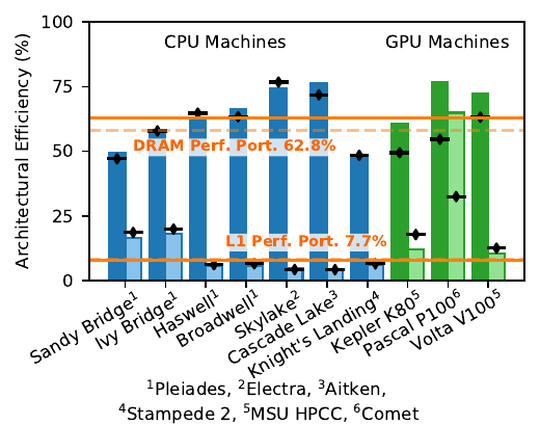
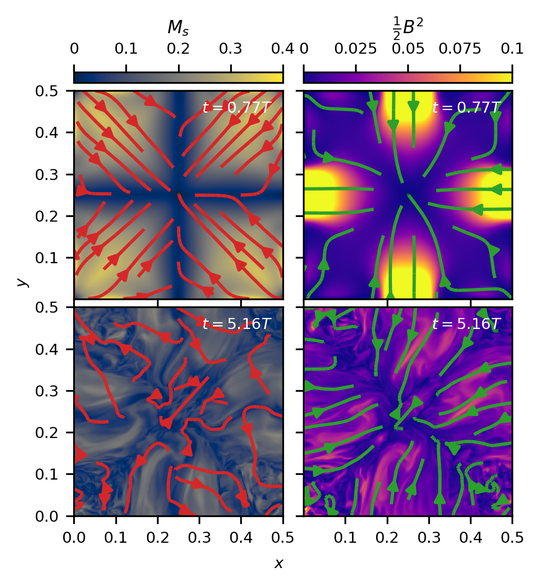
Publications
Experience
Research:
- Exascale Simulations of Galaxy Clusters on Frontier
- Support Performance Portable Astrophysics at LANL
Research:
- Active Galactic Nuclei Feedback Models
- Magnetic Fields in Galaxy Clusters
- Magnetohydrodynamic Turbulence
- Performance Portable Exascale Astrophysics Codes
Teaching:
- Teaching Assistant for Introduction to Astronomy
- Teaching Assistant for Parallel Computing
Research:
- Robust schemes for relativistic hydrodynamics
- IMEX methods for relativistic two-fluid electrodynamics
Research:
- Radiation hydrodynamics via ray tracing techniques for meshless hydrodynamics
- Pop III Star Formation
Research:
- Relativistic magnetohydrodynamics on GPUs
Teaching:
- Helped write lab manuals on numerical methods
Contact
- glines@lanl.gov
- LANL MS-B283 P.O. Box 1663, Los Alamos, NM 87545