K-Athena
 Performance-Portability of K-Athena across architectures
Performance-Portability of K-Athena across architectures
K-Athena is a partial conversion of Athena++, using Kokkos for performance portability, meaning that it runs efficiently on CPUs and GPUs. The code is a precursor to the Parthenon and AthenaPK projects, implementing only uniform grids efficiently when running on GPUs. However, the code was a valuable proof of concept for a performance-portable magnetohydrodynamics code, allowing future exascale simulations to be unconstrained by niche architectures.
K-Athena is publicly available on gitlab.
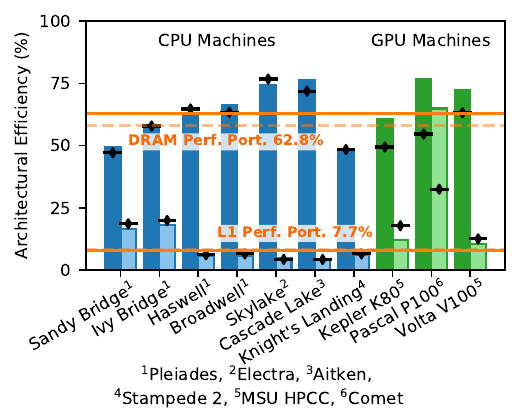
As part of the development effort, we quantified the performance portability of code using roofline models. We constructed roofline models on each of the CPU and GPU devices on which we tested K-Athena. Roofline models allow estimations of the theoretical peak throughput of a code as limited by its arithmetic intensity (the number of operations execute per byte loaded) and by the bandwidths and computational throughputs of the hardware. By comparing the actual efficiency achieved to the theoretical efficiency for each architecture, we obtain a performance efficiency for each machine that can be directly compared, even if the architectures are very different.
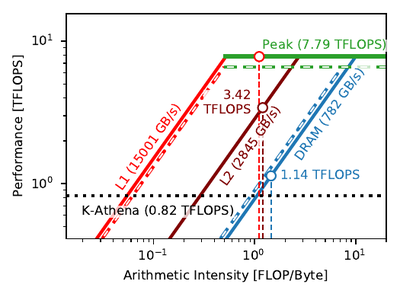
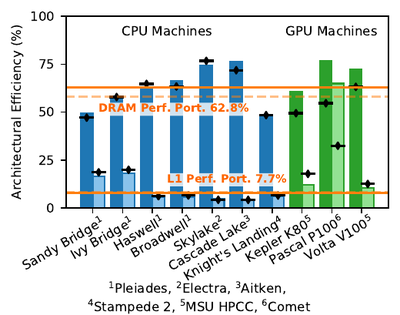
Our full method description and performance analysis can be found in IEEE Transactions on Parallel and Distributed Systems.
Forrest Glines
Metropolis Postdoctoral Fellow in Exascale Computational Astrophysics
Developing exascale-capable performance-portable astrophysics simulations